When I started running multiple LLM agents in parallel, I burned through a quarter of my Anthropic monthly limit in three days because I was nursing each one. Restarting the long ones when they went off the rails. Hand-curating context windows. Crafting bespoke system prompts. Watching specific sessions like a worried parent.
The waste was not the tokens. The waste was the model in my head.
I was treating my agents the way ops teams treated servers in 2008: as pets. Named, hand-tuned, irreplaceable. Each one a small individual project of mine. The day I stopped doing that — the day I started treating agents as cattle — was the day they actually started doing useful work at scale.
This is the framing decision that sits underneath every other technical choice I make about LLMs in production. It pre-dates the architecture decisions. It pre-dates the framework picks. It is, more than any individual tool, what separates “interesting demo” from “system that runs unattended.”
The metaphor’s origin
Bill Baker, an engineer at Microsoft, popularized “pets vs. cattle” sometime around 2012 to describe the shift from artisanal server management to fleet-scale operations. The pet was the box you named after a Norse god, ssh’d into to fix manually, panicked about when it went down. The cow was the AMI you spun up in an autoscaling group, terminated without ceremony when it misbehaved, and replaced from the same template five seconds later.
The shift the industry made — from pets to cattle — was not primarily about scale. It was about amortizing the cost of operating things. You cannot afford to know every server’s name when you have ten thousand of them. The cattle model says: build the inputs, build the lifecycle, observe the outputs, and stop investing in any individual instance.
LLM agents in 2025 are sitting roughly where servers sat in 2010. Most people are running pets. The cattle model exists, but it requires more infrastructure than most teams have built yet, and the framing has not made it into the public conversation.
What pet agents look like

You probably already know whether you are running pets, but the symptoms:
- You have a long-lived chat session you have spent hours curating context for, and you actively mourn the day you have to start a new one.
- You hand-tune a system prompt for a specific task, then never reuse it on a different task because it would not transfer.
- When the agent goes off the rails mid-task, you intervene. You re-prompt. You correct. You steer.
- You measure success by the quality of any one output, not the throughput of the system.
- You are the orchestrator. The agent is the worker. Both jobs cost your attention.
- The cost of failure is high enough that you avoid letting it run unsupervised.
Pet agents are not bad. They are the right tool for high-judgment, one-off, exploratory work. The bug fix you cannot describe well enough for autonomous work. The design conversation that benefits from a back-and-forth. Anything where the value of the output justifies the cost of your attention.
The trap is using pet agents for work that is bulk, repetitive, or asynchronous. That is where the model breaks.
What cattle agents look like
The cattle model has a few non-negotiable properties:
Headless. The agent does not chat. It receives a prompt, does work, exits. The exit code and the diff it produced are the entire interface. There is no human in the loop during the run.
Stateless. Each invocation reconstructs its own context from durable inputs. Same task, same context, same prompt — every time. If the worker dies mid-run, another worker starts the same task fresh from the same state. No “resuming” a session.
Replaceable. Workers are anonymous. Identified by NATO-alphabet identifiers (alpha, bravo, charlie) — interchangeable enough that the names are deliberately content-free. When a worker fails, you do not investigate that worker. You investigate the task it was working on, then dispatch another worker.
Observed at the herd level. You do not look at individual sessions. You look at fleet metrics: tasks completed per hour, cost per task, failure rate by category, queue depth. The unit of analysis is the herd, not the cow.
Governed at the fleet level. Spend caps, rate limits, weekly quotas — all enforced at the orchestrator, not the agent. No agent can spend more than the herd is allowed to spend, regardless of what the agent decides to do.
Concretely, this is what NEEDLE does. A worker is a tmux session running a deterministic state-machine loop: select the next task from a shared queue, claim it atomically, build the prompt from the task definition, dispatch to a headless CLI (Claude Code, OpenCode, Codex, Aider — agent-agnostic), wait for an exit code, classify the outcome, handle it, loop. The agent does the fuzzy work; the orchestrator handles every other dimension.
It is unromantic on purpose. The agent is a black box that produces work; the orchestration is the part you can reason about.
What you give up
Treating agents as cattle has real costs. Anyone who tells you otherwise has not actually run them this way:
You give up the warm context. A pet session, after an hour of back-and-forth, has accumulated a lot of nuance: corrections you made, dead ends you ruled out, preferences you taught it. Cattle agents start cold, every time. Whatever you have not encoded into the task definition is gone.
This forces you to write task definitions seriously. The work that used to live in your conversation history now has to live in the bead, the prompt template, the reference docs. It is more discipline up front and less recovery in the moment.
You give up the moment-to-moment steering. When a pet agent starts heading the wrong way, you stop it. Cattle agents finish the wrong way. They produce a bad output, the orchestrator classifies it as failure, the task gets retried — possibly with the same wrong approach, possibly with a different worker that happens to be configured differently.
This forces you to be explicit about what wrong looks like. Acceptance criteria become real artifacts, because the orchestrator needs to evaluate them automatically. “I will know it when I see it” is not a thing cattle can implement.
You give up the artisan’s pride. Each pet session has the satisfying texture of “we built this together, you and the agent.” Cattle is fungible by design. You stop having a relationship with any specific worker. You only have a relationship with the throughput of the system.
This is the part most people resist hardest. It is genuinely a loss.
What you cannot have without cattle
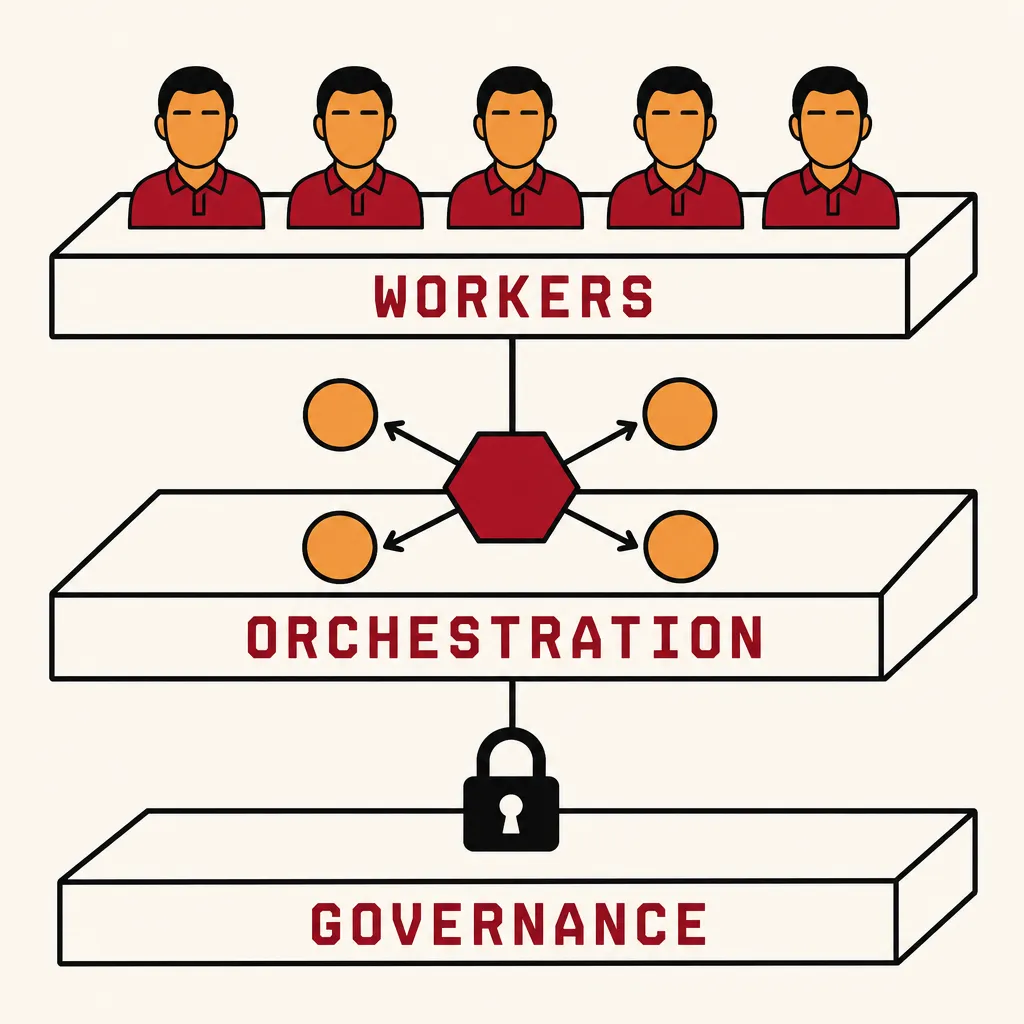
In exchange, you get three things that are simply not available in the pet model:
Parallelism. I have run twenty NEEDLE workers concurrently on the same workspace. They coordinate through atomic claims on a shared bead queue (SQLite transactions guarantee exactly one worker wins each claim). I cannot manage twenty pet agents. Nobody can. The pet model has a hard ceiling around three or four sessions before the human becomes the bottleneck.
Cost governance. When I had pet agents, I was the spend control. I noticed when one was running long and stopped it. I noticed when one was being expensive and intervened. With twenty headless workers running unattended, I cannot be the spend control — the orchestrator has to be. claude-governor caps spend, throttles workers, and gates against weekly Anthropic limits. None of that is meaningful in a pet model because the pet has only one operator and that operator is paying attention.
Failure as a normal mode. A pet session “failing” is a small disaster. You console yourself, restart, try to recover the context. A cattle worker failing is expected. The orchestrator has an explicit handler for every outcome a worker can produce — success, failure, timeout, crash, race-lost, queue-empty. None of those is exceptional. Each has a defined recovery path. Workers fail constantly; the system does not.
This last point is the one I underestimated longest. In a pet model, failure is the thing you try to avoid. In a cattle model, failure is just one more outcome the orchestrator routes. You stop optimizing for “agents that don’t fail” and start optimizing for “an orchestrator that handles failures cleanly.” That second target is much more tractable.
The honest tradeoff
This is not a story where one model wins. They are tools for different shapes of work.
Pets are right when:
- The task requires high-judgment back-and-forth.
- The unit of value is one specific output, not throughput.
- You cannot fully specify success in advance.
- The cost of getting it wrong is high enough to justify your attention.
Cattle are right when:
- The work is bulk, queueable, asynchronous.
- Success is specifiable enough that the orchestrator can classify outcomes.
- Throughput matters more than any individual artifact.
- The economics only work if a human is not in the loop.
Most teams I see are running pet workflows on tasks that should be cattle. The fix is not just buying more agents — it is rewriting the task so that an unattended agent can succeed at it. That rewrite is the actual work. Once the task is specified well enough for cattle, the orchestration layer is a handful of weekends.
The question I now ask
Before I build anything new with LLMs, I ask one question:
Could a stateless, headless worker that does not know my name complete this task with only the inputs I write down?
If the answer is yes, it goes into the cattle pipeline.
If the answer is no, I do one of three things:
- Specify the task harder until the answer becomes yes.
- Decide it is genuinely a pet task and budget my attention accordingly.
- Decide LLMs are the wrong tool for this and write the code myself.
The point is not that one answer is correct. The point is that I now make the decision, deliberately, instead of defaulting to pets because pets are what the chat interface trained me to do.
The chat interface is wonderful for what it is. It is the tutorial. It is not the production system.
— Jed
If you want to see what the cattle model looks like as code: NEEDLE is the orchestrator (Rust, deterministic state machine, K8s-native fleet); claude-governor is the fleet-level spend and quota gate; ccdash is the herd-health TUI. All three exist because none of this works without all three.