-
Trust is a property of the system, not the agent
agents
A near-miss with a git flag once put three volumes of real data one sync cycle from deletion — caught by luck, not by design. The right fix wasn't more vigilance. It was building the trust into the system itself: an agent doesn't need to be trusted, an action needs to be cheap to undo.
-
What breaks when you run twenty agents at once
agents
A failure taxonomy from a year of running coding-agent fleets unattended. Eight ways a fleet dies, none of which involve the model — and the operational discipline they add up to.
-
The agentic coding ladder is a list of things you give up
agents
Steve Yegge's eight levels read the climb by how much you trust the AI. Here's a complementary lens on the same ascent: measure it by what you give up at each rung — which is why some people skip rungs entirely, having no old coding habits to undo. It starts with the search bar and ends with something none of us can name yet.
-
Ending is better than mending
agents
Huxley wrote it as dystopian propaganda for mindless disposability. In the agent era the economics it described have quietly become correct — for code. When the agent produces the wrong artifact, mending spends your scarce attention; ending spends cheap tokens. Revert the commits. Sometimes nuke the repo.
-
Don't let the agent grade its own homework
agents
An agent reporting 'done' is the actor grading its own work. The cheapest guard against silent failure is an independent observer — a second agent, a separate tool, or the live artifact itself. Interactively you spawn the watcher by hand; in a fleet it's a validation gate. Same principle, two scales.
-
Anchor on a fact the model can't see
agents
An agent's confidence is uncorrelated with whether it's right. The cheapest correction you can make is to hold out one ground-truth fact it never had in context — usually a number — and check its output against that. Works the same whether you're watching one session or auditing a fleet's reports.
-
'No' is not an instruction
agents
The cheapest way to steer an agent is also the most-skipped one. A rejection tells the agent what not to do; the space of 'not that' is enormous. Name the alternative in the same breath and you re-steer in one turn instead of N. True for one pet session and for twenty cattle workers.
-
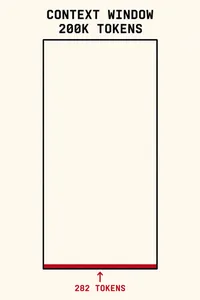
Benchmarks measure a model you are not running
agents
SWE-bench problems have a median of 282 tokens. HumanEval: 117. MBPP: 16. Every major coding benchmark evaluates a model operating with essentially an empty context window — which is almost never the condition you run in. Unless you are running cattle.
-
The plan is the prompt
agents
Why a detailed plan document is the most token-dense artifact you will write for a headless agent fleet. What a plan actually needs to contain, how it anchors the genesis bead hierarchy, and why a bad plan is more expensive than it looks when twenty workers are running it simultaneously.
-
The unit economics of running cattle
agents
How to make the math work when twenty headless workers are spending money without you. Why the pet model has no built-in cost discipline, what the cattle model requires, and what to measure when tokens are the wrong unit.
-
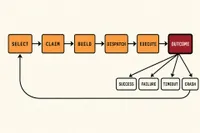
Deterministic state machines for non-deterministic agents
agents
Why agent orchestration needs explicit outcome handlers. The control structure that lets twenty headless workers run unattended without the operator becoming the loop.
-
Pet agents vs. cattle agents
agents
The infrastructure metaphor that decided how I build with LLMs. Why most people are running pets, why pets do not scale, and what cattle actually require.
-
A new place for opinions and biases
meta
Why I started these notes, what I plan to put on this surface, and what to expect.