-
What breaks when you run twenty agents at once
agents
A failure taxonomy from a year of running coding-agent fleets unattended. Eight ways a fleet dies, none of which involve the model — and the operational discipline they add up to.
-
The agentic coding ladder is a list of things you give up
agents
Steve Yegge's eight levels read the climb by how much you trust the AI. Here's a complementary lens on the same ascent: measure it by what you give up at each rung — which is why some people skip rungs entirely, having no old coding habits to undo. It starts with the search bar and ends with something none of us can name yet.
-
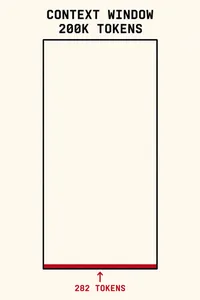
Benchmarks measure a model you are not running
agents
SWE-bench problems have a median of 282 tokens. HumanEval: 117. MBPP: 16. Every major coding benchmark evaluates a model operating with essentially an empty context window — which is almost never the condition you run in. Unless you are running cattle.
-
The plan is the prompt
agents
Why a detailed plan document is the most token-dense artifact you will write for a headless agent fleet. What a plan actually needs to contain, how it anchors the genesis bead hierarchy, and why a bad plan is more expensive than it looks when twenty workers are running it simultaneously.
-
The unit economics of running cattle
agents
How to make the math work when twenty headless workers are spending money without you. Why the pet model has no built-in cost discipline, what the cattle model requires, and what to measure when tokens are the wrong unit.
-
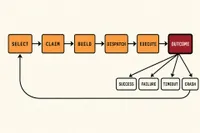
Deterministic state machines for non-deterministic agents
agents
Why agent orchestration needs explicit outcome handlers. The control structure that lets twenty headless workers run unattended without the operator becoming the loop.
-
Pet agents vs. cattle agents
agents
The infrastructure metaphor that decided how I build with LLMs. Why most people are running pets, why pets do not scale, and what cattle actually require.