The engine room
Copy linkSix NEEDLE workers, one shared queue. Each worker independently runs the same loop — SELECT → CLAIM → BUILD → DISPATCH → EXECUTE → OUTCOME — pulling beads from bead-forge with atomic claims: exactly one worker wins each bead, losers move on to the next. Success closes a bead, failure re-queues it, timeout defers it. No dispatcher, no coordinator — just the loop, running unattended. The workers aren't uniform, either — each one drives a different agent harness (Claude Code, Codex, Goose, Pi) and model through the same adapter contract: prompt in, exit code out.
Beads shown are simulated.
A worker crashes mid-task. A model-provider rate-limit kicks in for nine minutes. Two workers race for the same task and one of them loses. The agent finishes successfully but produces output that doesn’t compile. Same workspace, same hour, four different outcomes — and zero of them are wrong. They are exactly the outcomes a long-running headless agent fleet should expect.
The question is not how to prevent any of those. The question is what happens after each one.
If your answer is some flavor of “I’ll go look,” you are still running pets. The cattle model needs an answer that does not involve a person — and the answer has to be defined before the outcome, not improvised after it.
This is the post about that answer.
The shape of the problem
Existing agent orchestration tools cluster into two shapes. Neither one quite fits.
Conversational frameworks — LangGraph, AutoGen, CrewAI. These assume a chat loop with a human-in-the-loop or another LLM, and they are good at that. They are bad at sustained autonomous work because the entire abstraction is the conversation. When the conversation ends, the abstraction ends. Recovering from a crash means starting over and hoping the new conversation lands in roughly the same place. Failure modes are vague — “the agent went off the rails” — because the framework never modeled what “the rails” were.
Workflow engines — Temporal, Argo Workflows, Inngest. These are excellent at deterministic step orchestration. They assume each step is code that you wrote, that produces a known shape of output, and that fails in known ways. Plug a non-deterministic agent into a Temporal workflow and the type system gives up: the agent’s output is a string, the failure mode is “any exception with any message,” and the workflow’s retry logic cannot tell a transient rate-limit from a logic bug from “the agent gave up.”
The missing middle is a deterministic state machine that drives non-deterministic agents. The orchestrator is rigid; the worker is fuzzy. The orchestrator’s job is to enumerate every shape the fuzziness can produce and route each shape to a known handler. The agent’s job is to produce one of those shapes.
NEEDLE is the shape this idea takes when you write it down. The rest of this post is what falls out.
The thesis
If an outcome can happen, it has a handler. If it doesn’t have a handler, it cannot happen.
Every state transition in NEEDLE has an explicit handler. There are no implicit fallbacks. There is no match _ => continue. There is no “swallow the error, log a warning, hope nobody notices.”
This sounds like a small constraint. It is the largest constraint in the system, and almost everything else falls out of it.
What this looks like in practice
A NEEDLE worker is a loop that executes six steps:
- SELECT — query the bead queue for the next claimable task in deterministic priority order.
- CLAIM — atomically claim the task via a SQLite transaction. Exactly one worker wins.
- BUILD — construct the prompt from the task definition. Same task → same prompt, every time.
- DISPATCH — load the agent adapter (Claude Code, OpenCode, Codex, Aider, anything CLI) and invoke it.
- EXECUTE — wait for the agent to exit. The only inputs the orchestrator gets back are the exit code and what was written to disk.
- OUTCOME — classify what happened. Run the handler. Loop.
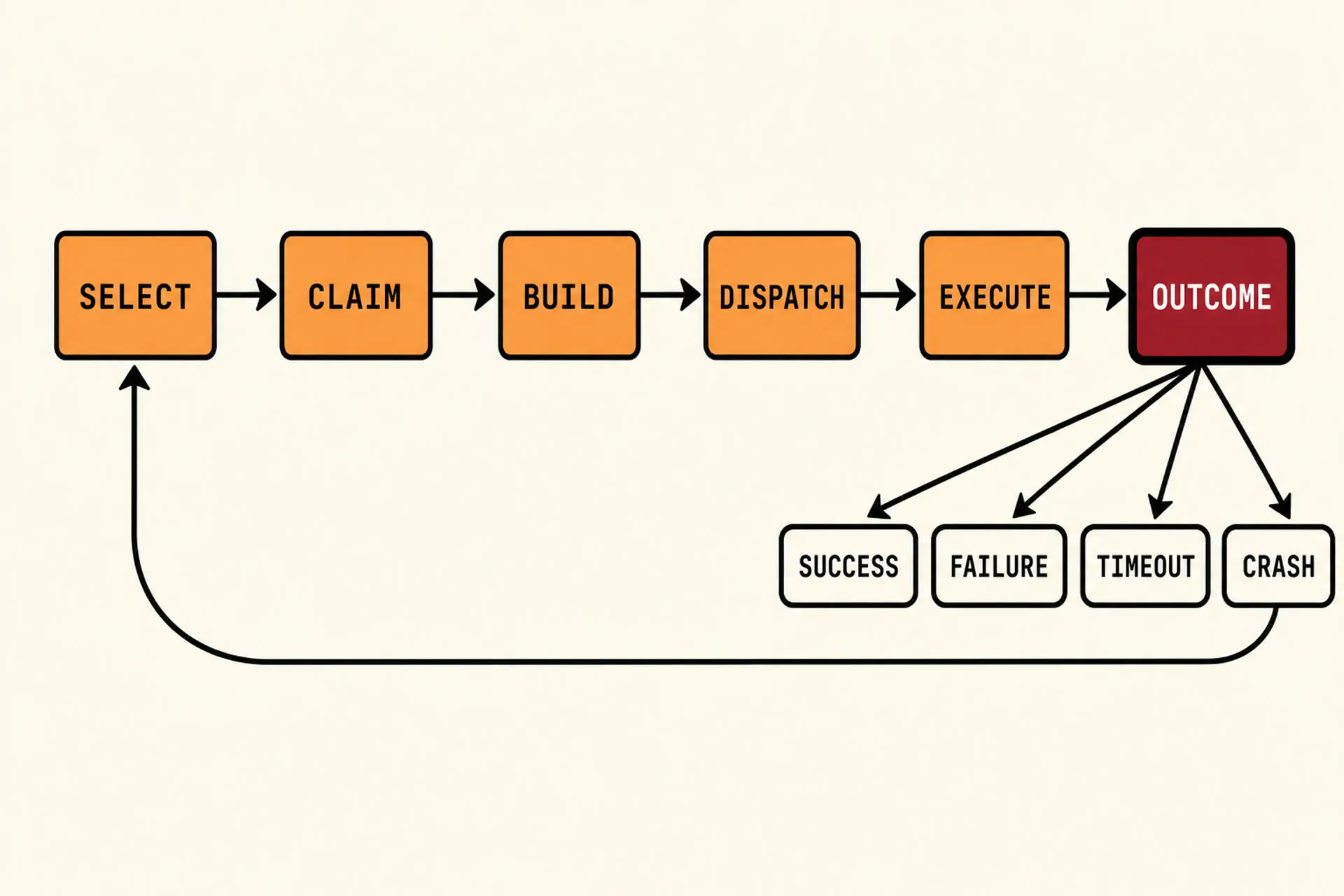
The first five steps are mechanical. Almost any orchestration framework can do them. The whole game is in step six.
Here is the OUTCOME table for one NEEDLE iteration:
| Outcome | Detection | Handler |
|---|---|---|
| Success | exit code 0, output validates | close the task, log effort, loop |
| Failure | exit code 1 | log failure reason, release the task, increment retry count, loop |
| Timeout | exit code 124 | release the task, mark deferred, loop |
| Crash | exit code >128 (SIGKILL, SIGSEGV, etc.) | release the task, create an alert task, loop |
| Race lost | claim transaction returned no row | exclude this candidate, retry SELECT |
| Queue empty | no claimable tasks | enter strand escalation: search other workspaces, do cleanup, alert if all strands exhausted |
Six rows. Every row has a handler. Every row was added because the absence of a handler caused a real bug.
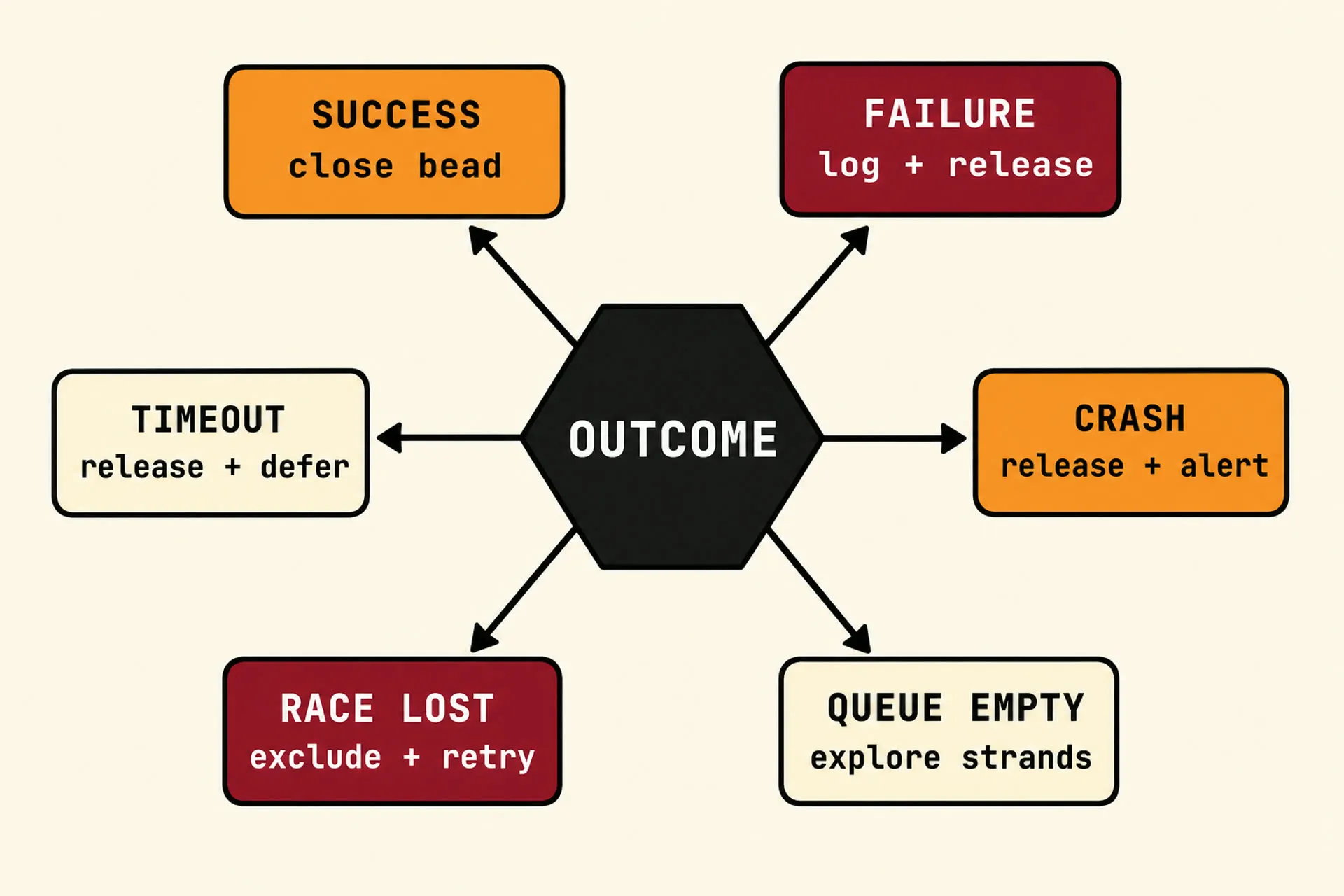
A few of those rows are worth dwelling on.
Race lost is its own outcome, not a failure. Two workers see the same top-priority task, both try to claim it, exactly one wins. The loser is not broken. It just needs to skip that task and try the next one. If you don’t model “race lost” as a first-class outcome, you end up with workers that retry endlessly on tasks they will never claim — or worse, with workers that crash with cryptic SQLite errors and get auto-replaced by an outer supervisor that has no idea what just happened.
Queue empty is its own outcome, not idle time. When a worker has nothing to do, that is a signal, not a non-event. It means: this workspace is exhausted, look elsewhere. NEEDLE has a strand escalation sequence for this — search other workspaces, do cleanup, propose alternatives for blocked tasks, etc. — but none of that runs unless “queue empty” is a recognized outcome that triggers it. A worker that just spins on an empty queue is wasting cycles and obscuring the signal that the queue is empty.
Crash is distinct from failure. A failure is the agent saying “I tried and produced nothing useful.” A crash is the agent dying without saying anything. They look superficially similar. They require different handlers: a failure increments a retry count and tries again; a crash creates an alert and may indicate something fundamentally wrong (the agent binary isn’t installed, the workspace is corrupted, the model provider is rejecting all requests). Conflating them is the difference between a system that self-heals and a system that thrashes.
What it costs
The deterministic state machine is not free. The cost shows up in three places.
Up-front enumeration. You have to sit down and think through every shape your worker can produce. This is harder than it sounds. The natural state of any human-built system is “I’ll add the handler when the bug actually happens” — which works fine for human-supervised work and is actively dangerous for unattended fleets. The first month of NEEDLE was mostly me producing new outcome rows because the system kept finding outcomes I hadn’t thought to enumerate.
Discipline against match _. Rust makes this discipline visible: a non-exhaustive match is a compiler error. Languages without exhaustiveness checks make it tempting to write a wildcard handler that does something reasonable. Wildcards are how state machines silently grow undefined behavior. The rule has to be: when a new outcome shows up, you stop, you name it, you give it a row in the table, and you write its handler. You do not add it to the wildcard.
Schema-first, not caller-first. When you discover a new outcome, you do not patch the call site. You go back to the type that represents the outcome and add a variant. Then the compiler tells you everywhere else that needs to handle the new variant. This is more friction than the alternative — but the alternative is an outcome enum that drifts from reality, with handlers that quietly stop being called.
What it’s worth
In exchange you get three things that are not available under any other model.
Workers fail predictably. Predictable failure is the foundation of recovery. A worker that returns garbage in a known failure mode — exit code 1, log line in a known format — is more useful than a worker that silently returns subtly-wrong output. The orchestrator can route the known failure; it has no leverage on the silent corruption. Designing for predictable failure means refusing to wallpaper over the failures you cannot classify, and instead either learning to classify them or rejecting the work.
The state machine is the contract; agents are the implementation. This is the property that lets NEEDLE be agent-agnostic. The state machine doesn’t know whether the worker is Claude Code, OpenCode, Codex, or Aider. It knows that the worker is something that takes a prompt and produces an exit code. Add a new agent and you add a YAML adapter file — no code changes. Drop a worse agent and replace it with a better one — same. The agents are parts; the state machine is the machine.
You can run twenty of these and reason about what the herd is doing. Twenty pet agents are unreasonable. Twenty deterministic state machines, each running the same six-step loop, are reasonable. You stop debugging individual workers and start debugging the outcome distribution — which row of the table is firing more often than it should? When the failure column trends up, you know to look at the prompts. When the timeout column trends up, you know to look at the model provider. The state machine made each worker’s behavior legible enough that the fleet’s behavior is also legible.
What I’d change
Three things, with the benefit of running this in production for a while.
Outcome classification should be richer than exit codes. Exit codes are a 0–255 alphabet. They are too coarse to express the difference between “agent gave up gracefully” and “agent gave up because the rate-limiter hit it.” Right now NEEDLE squints at stderr to disambiguate. If I rebuilt today, I would have agent adapters return a structured outcome envelope (JSON to a known sentinel path, or a stdout marker) instead of relying on exit codes alone. Exit codes would be the fallback when the envelope is missing.
Strand escalation should be a separate state machine. “Queue empty” routes to a sequence of fallback behaviors — search other workspaces, do cleanup, propose alternatives, alert if exhausted. Today that sequence is a function inside the OUTCOME handler for queue-empty. It really wants to be its own state machine with its own outcome table. Whenever a section of code starts growing its own enum of “what happened,” that is the system asking for a state machine.
Determinism in the orchestrator does not buy determinism in outcomes. Two NEEDLE workers running the same task will produce different outputs because the agent is non-deterministic. That is by design. But it means replaying the orchestration against a recorded outcome stream is not the same as replaying the work. If I rebuilt today, I would separate “orchestration replay” (deterministic) from “work replay” (impossible without the agent), and design the recording format to make the first kind of replay easy.
The question I now ask
Before I add an outcome handler — before I add any new state to a NEEDLE-like system — I ask:
What outcome am I making explicit, and what was my system doing about it before?
If the answer to the second part is “nothing, it was hidden in a wildcard,” that is the bug I am fixing. If the answer is “it was conflated with a different outcome,” that is also a bug. If the answer is “I am inventing this outcome to handle a hypothetical,” I do not add it. The state machine grows by making implicit outcomes explicit, not by adding speculative variants.
This is dual to the cattle question from the last post: can a stateless headless worker complete this with only the inputs I write down? Together they bound the design space:
- Cattle says: the agent must be replaceable.
- State machine says: the orchestrator must be exhaustive.
Either alone is a tarpit. Cattle without a state machine is a fleet of identical workers all failing in mysterious ways. A state machine without cattle is a beautiful enum that one operator hand-runs forever.
The combination is the system that runs unattended.
— Jed
Background: Pet agents vs. cattle agents — the mental-model shift this post sits on top of. Code: NEEDLE — the deterministic state machine described here, in Rust.