The first time I ran headless agents in earnest, I burned through a quarter of my Anthropic monthly limit in three days. I told that story already as a parable about treating agents as pets. It is also a story about money — and the money story is the one almost nobody plans for before it happens to them.
The pet model has a hidden cost-control mechanism that nobody designed deliberately and nobody notices until they remove it. The cattle model removes it. If you do not replace it with something explicit before the workers go headless, you find out about the gap at the bottom of an invoice.
This is the post about the replacement.
The pet model’s hidden subsidy
When you run a pet agent, you are the spend control. Not metaphorically — literally. The reason your bill stays sane is that your attention is the bottleneck. You can only watch one or two sessions at a time. Each session can only spend money while you are in it. When you walk away from the keyboard, the spending stops because the conversation stops.

This is invisible until you scale. As long as the human is in the loop, three things happen automatically:
- You notice runaways. The agent that has been chewing on the same prompt for ten minutes producing nothing is something you see and stop. You do not need a metric for it. You see the spinner.
- You pace yourself. Token-heavy operations — long context windows, large diffs, tool calls with big outputs — get throttled because you are the one initiating them. You feel the lag and back off.
- You self-throttle on quota. When the dashboard creeps up, you slow down. The dashboard is your conscience. The agent has no conscience.
None of those mechanisms exist in cattle. The agent does not see its own cost. The agent does not see the dashboard. The agent does not get tired. Twenty headless workers running unattended, each invoking expensive tool calls in tight loops, will produce a bill that bears no relationship to the value of the work — unless something between them and the provider says no.
The pet model’s economics work because the human is the rate-limiter. The cattle model’s economics work because something else is the rate-limiter. That something else is the actual subject of this post.
Tokens are the wrong unit
The first instinct, when the bills get scary, is to start counting tokens. Token-counting feels rigorous. The provider exposes per-call usage. You can build dashboards. You can say “this prompt averages 12,000 input tokens, this one averages 40,000” and feel like you are doing the work.
It is the wrong unit.
Tokens are an input cost, not an output measurement. A worker that burns 200K tokens to close one bead and a worker that burns 800K tokens to close five beads — the second worker is four times cheaper per outcome, even though it spent four times more on tokens. If you optimize the token line you will end up trimming context windows on the second worker until it stops being able to close beads at all, and you will congratulate yourself on the savings.
The unit that matters is cost per closed outcome. A bead closed. A test passing. A PR merged and reviewed. The denominator is the work the system actually delivered, not the inputs it consumed getting there. Token cost without an outcome attached is just spend.
This is harder to measure. It requires the orchestrator to know when a worker produced a real outcome — which is the same exhaustive-handler discipline from the previous post showing up in a different form. If your state machine cannot tell success from failure, it cannot tell expensive-but-productive from expensive-and-wasted, and you will optimize the wrong column.
The orchestrator that classifies outcomes is also the orchestrator that can compute outcome cost. They are the same machine, doing the same work, for two reasons.
Cost governance is its own component
Once you accept that the human cannot be the spend control, the question becomes: where does the spend control live?
It does not live in the worker. The worker is fungible by design — and a worker that polices its own budget is not fungible, because some workers will refuse work that other workers would accept. It does not live in the provider, because providers are happy to sell you whatever you will buy. It does not live in the orchestrator, because the orchestrator’s job is to dispatch work, not to mediate the financial contract with each provider.
It lives in a dedicated component sitting between the workers and the providers. A proxy that every model call passes through, with three jobs:
Cap spend. A hard ceiling on outflow per window — daily, weekly, monthly. When the cap is hit, calls return a structured error and the orchestrator handles it as just another outcome (route to the “rate-limited” handler, sleep the worker, retry later). The cap is not a soft warning. It is enforced at the request layer.
Throttle in-flight concurrency. A semaphore on simultaneous calls. Twenty workers does not mean twenty concurrent provider requests; the proxy holds a smaller number and queues the rest. This is what protects you when a tight retry loop in the orchestrator turns into an accidental DDoS of yourself.
Gate against quota. Subscription plans (Anthropic Max, Z.AI Max) have weekly or monthly windows. The proxy tracks burn against those windows independently of what the provider reports, and starts shedding load before the provider does. You hit your own ceiling before the provider hits theirs, because hitting the provider’s ceiling is the bad failure mode.
claude-governor is what this looks like in my setup. It is unromantic plumbing — a Rust process that holds the Anthropic API key, exposes a local HTTP endpoint that workers call instead of api.anthropic.com, and enforces all three policies above. There is nothing clever about it. The cleverness is that the workers do not know it exists; they just see model calls succeed or fail. The policy is hidden behind the same interface the model itself uses, which is the only place a policy of this kind can live without leaking into every worker.
Run a portfolio, not a provider
There are two pricing models in this market and they do completely different things to your unit economics.
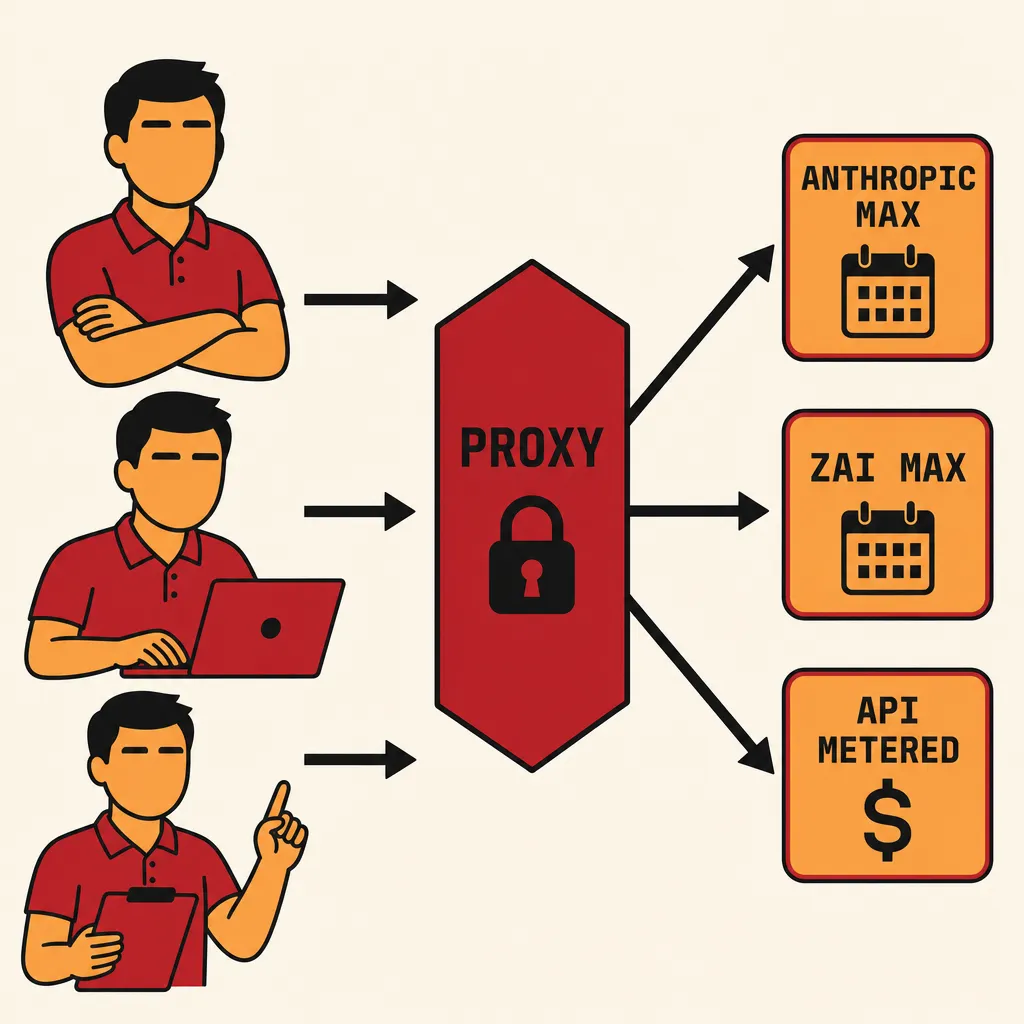
Subscriptions (Anthropic Max, Z.AI Max) cap your downside. You pay a fixed amount per month, you get a quota window, and if you exceed it you get cut off — not charged more. The cost per outcome is bounded above. The downside is bounded; the upside is bounded too. Subscriptions are how you fund sustained throughput, the steady drumbeat of cattle work that runs every hour of every day.
Metered API caps nothing. You pay for what you use. There is no ceiling. A bug in your retry loop can turn into a five-figure invoice overnight if there is no governor in front of it. The upside is real — metered access is how you handle bursts, spikes, one-off batches that exceed the subscription window without burning the next week’s quota. The downside is unbounded. You only run metered traffic with the governor enforcing a hard cap, no exceptions.
A healthy fleet runs both. The subscription is the floor — committed throughput at a known cost. The metered API is the surge capacity. The orchestrator does not care which is which; the proxy makes the routing decision based on which subscription has remaining quota, which model the task asked for, and how much headroom the daily metered cap has.
The mistake I have watched people make repeatedly is going all-in on metered API “for flexibility.” You get the flexibility. You also get a cost structure that scales linearly with how aggressive your retry policy is, which is exactly the wrong elasticity to give an autonomous fleet.
Quota observability is asymmetric
The proxy needs to know how much you have spent against each window. This sounds trivial. It is not, because the providers expose this information unevenly.

Anthropic exposes weekly limit headers on every API response. The governor reads them, knows where it is in the window, and shapes traffic accordingly. You can build proper closed-loop control because the loop has a sensor.
Z.AI exposes nothing programmatic. There is no quota endpoint. There are no rate-limit headers. The only place you can see your usage is the web dashboard, which is fine for a human checking in once a day and useless for a process that needs to make a decision every second. The governor is flying blind on Z.AI quota — until the wall, when the API starts returning rate-limit errors and you reverse-engineer what just happened.
The fix is to model your own quota independently. Measure outflow at the proxy, count it against your own ledger, and treat that as the source of truth — not what the provider reports, because the provider may not report at all. “You are out of quota” should be a fact your governor knows before the provider tells you, because the only signal the provider gives some of these subscriptions is the failure itself.
This is more work than it should be. It is the cost of operating against providers whose business model has not yet caught up with the operational needs of customers running unattended fleets. It will get better. Until then, the governor’s quota model is a thing you maintain by hand.
The cheap-restart reflex
The pet operator has one cost-control reflex that the cattle operator should preserve and amplify: when a worker is stuck, kill it.
In the pet model this is intuitive. You see the agent thrashing, you stop it, you start over. The cost of the restart is small. The cost of letting it grind for another five minutes is large.
In the cattle model the same reflex is correct, but the operator cannot apply it manually because the operator is not watching. The reflex has to be built into the orchestrator. Three bounds, enforced at the worker level:
Time-bounded executions. A worker that has been running on the same task for longer than the budget gets killed. The handler is the timeout handler from the previous post — release the task, mark deferred, loop. No appeal. No “but it might be making progress.” Long-tail tasks are almost always stuck tasks.
Token-bounded executions. A worker that has emitted more than N tokens of output on a single task gets killed. Most real outcomes fit comfortably in a budget. The ones that exceed it are usually agents in some kind of loop — emitting the same diff over and over, retrying the same failing tool call, repeating themselves with minor variations.
Iteration-bounded executions. A worker that has invoked the model more than N times on a single task gets killed. This catches the case the previous two miss: a worker that produces small, fast, expensive calls in tight succession. None of them individually trips the time or token bounds. The count does.
These three bounds together convert “the worker decides when to stop” into “the orchestrator decides when to stop.” Which is the only correct allocation of that decision in a cattle system, because the worker has no skin in the game and the orchestrator has all of it.
A worker killed early might have been about to succeed. That is fine. The task goes back on the queue, gets picked up by another worker, possibly with a different prompt or a different model, and tries again. The cost of a wasted execution is a single bounded run. The cost of an unwasted runaway is unbounded.
Cheap restart, every time.
What I’d change
Three things, in order of how often I think about them.
Outcome cost should be a first-class metric, not a derived one. Today I compute cost per closed bead by joining provider invoices to the orchestrator’s outcome log after the fact. It works but it is asynchronous — I find out about expensive failures after they have already happened. The proxy already knows, in real time, what each call cost. The orchestrator already knows what task each call belonged to. The metric should be emitted live: this bead just closed, here is what it cost, here is whether that is in line with the historical distribution. If it is an outlier, alert immediately.
Per-task budgets should be configurable, not fleet-wide constants. Right now the time / token / iteration bounds are global. Some tasks legitimately want bigger budgets — a complex refactor across many files genuinely needs more space than a one-line fix. The bead should declare its budget. The orchestrator should enforce it. Today everything gets the same budget and I either set it too low for hard tasks or too high for easy ones.
The governor should expose its policy decisions as a stream. Right now when the governor decides to throttle, the worker just sees a delayed call. There is no record of why it was delayed, against which window, or what the governor’s view of remaining headroom was. When you go to debug “why did the fleet’s throughput drop in this hour,” the governor’s reasoning is opaque. It should not be. Every policy decision the governor makes — throttled, capped, routed-to-metered, gated-by-quota — should be a structured event that the observability stack can query.
The question I now ask
Before I run any new workload on the cattle pipeline, I ask:
What is each dollar of spend supposed to produce, and how would I know if it didn’t?
Both halves matter. The first half forces you to attach a denominator to the spend — you are not buying tokens, you are buying outcomes. The second half forces you to instrument the answer — if you cannot tell whether the spend produced the outcome, you cannot govern it. You are just hoping.
The pet model lets you skip both halves because your attention substitutes for both. You see the outcome (or its absence) directly. You see the spend (or its absence) directly. The cattle model takes both signals away from you and forces you to rebuild them in the orchestrator and the governor — explicitly, before the workers go live.
If you have not built that, you do not have a cattle system. You have a pet system with the supervision removed, which is a different thing. It looks the same right up until the bill arrives.
— Jed
If you want to see the governor side: claude-governor is the Rust proxy described here. The fleet side — workers, state machine, outcome handling — is NEEDLE. Together they bound the system from both ends: NEEDLE decides what work to do; claude-governor decides what that work is allowed to cost.