-
Benchmarks measure a model you are not running
agents
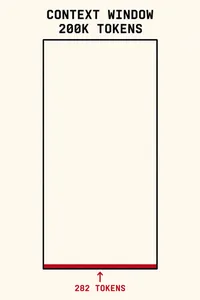
SWE-bench problems have a median of 282 tokens. HumanEval: 117. MBPP: 16. Every major coding benchmark evaluates a model operating with essentially an empty context window — which is almost never the condition you run in. Unless you are running cattle.